Stop "context rot" from degrading AI results. Discover how recursive prompting and context folding break complex tasks into reliable units, while shared prompt libraries and token efficiency transform AI into a scalable team asset.
The same AI model, given broadly similar tasks on different days, produces results that vary considerably in quality, depth and usefulness. That inconsistency is a direct consequence of how large language models (LLMs) are structurally designed to process a request. Every word is first converted into a numerical unit called a token, roughly equivalent to four characters of text. Non-English text, however, typically uses more tokens. The model processes those tokens through a mechanism called attention, which determines how much weight each token gives to every other token in the input.
The Cost of Complexity
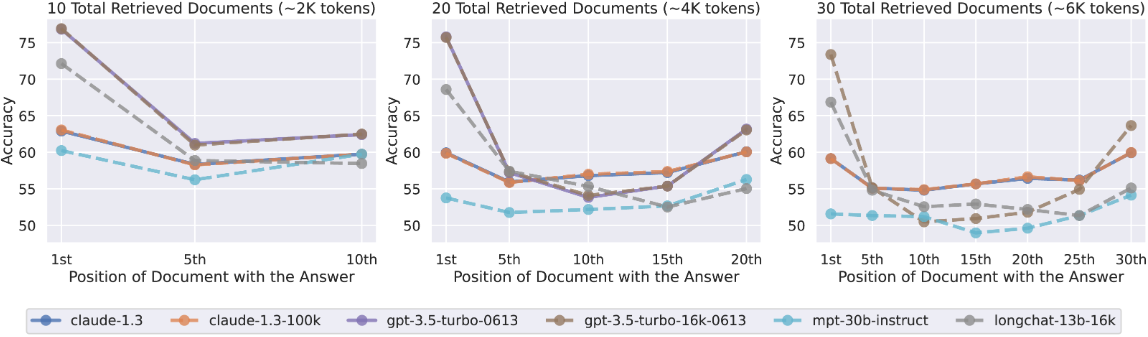
When a prompt is short and well-scoped, attention distributes cleanly across it. Yet, as a prompt grows longer, including more instructions and background information, the model's ability to maintain coherence begins to decline as there are more signals to balance. The quality of its output reflects that enhanced load. A 2024 study found that model performance degrades by more than 30% when relevant information sits in the middle of a long context, even in models explicitly designed for extended inputs.
This means that feeding a language model an enormous amount of background text is a bit of a double-edged sword. More context can sharpen the results, but it also gives the model far more to trip over, which can actually dent its accuracy. Does the extra context add real value or does the model simply lose its way when the input gets too heavy? The answer usually comes down to the specific task.
This widely observed but underappreciated phenomenon is known as context rot, where the output reflects the dilution of the prompt requirements. Maintaining quality as task complexity grows, while keeping costs manageable as volume increases, points to the need for restructuring how the interaction is built rather than hunting for a cheaper model or writing shorter prompts. The impact of context rot can be limited to a certain degree by positioning the most relevant information at the start or end of a prompt, necessitating a clear overview of which factors have the highest strategic importance right from the outset of a task.
A further complication is that teams rarely have clear visibility into how many tokens a given interaction will actually consume before it runs. Usage depends on the length and complexity of the conversation, the features in use and which model is selected, without specifying a precise figure in advance. This uncertainty makes overloaded prompts doubly costly as they are difficult to budget for.
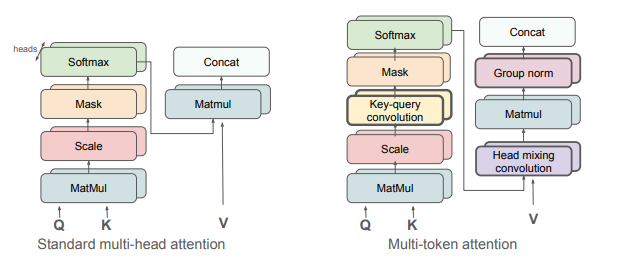
In most LLMs, each attention weight is determined by comparing a single query token against a single key token. This one-to-one matching places a ceiling on how much information the model can use when deciding which parts of a prompt are relevant to a given output.
From Single Prompts to Structured Workflows
Meta's research into Multi-Token Attention (MTA) proposes a direct solution. Rather than each token attending independently, MTA blends them together and allows neighbouring tokens to influence each other's attention weights. The result is a model that locates relevant context using richer, more nuanced signals. This means the model is better equipped to handle complex, layered prompts, where meaning is distributed across multiple sentences rather than concentrated in a single phrase.
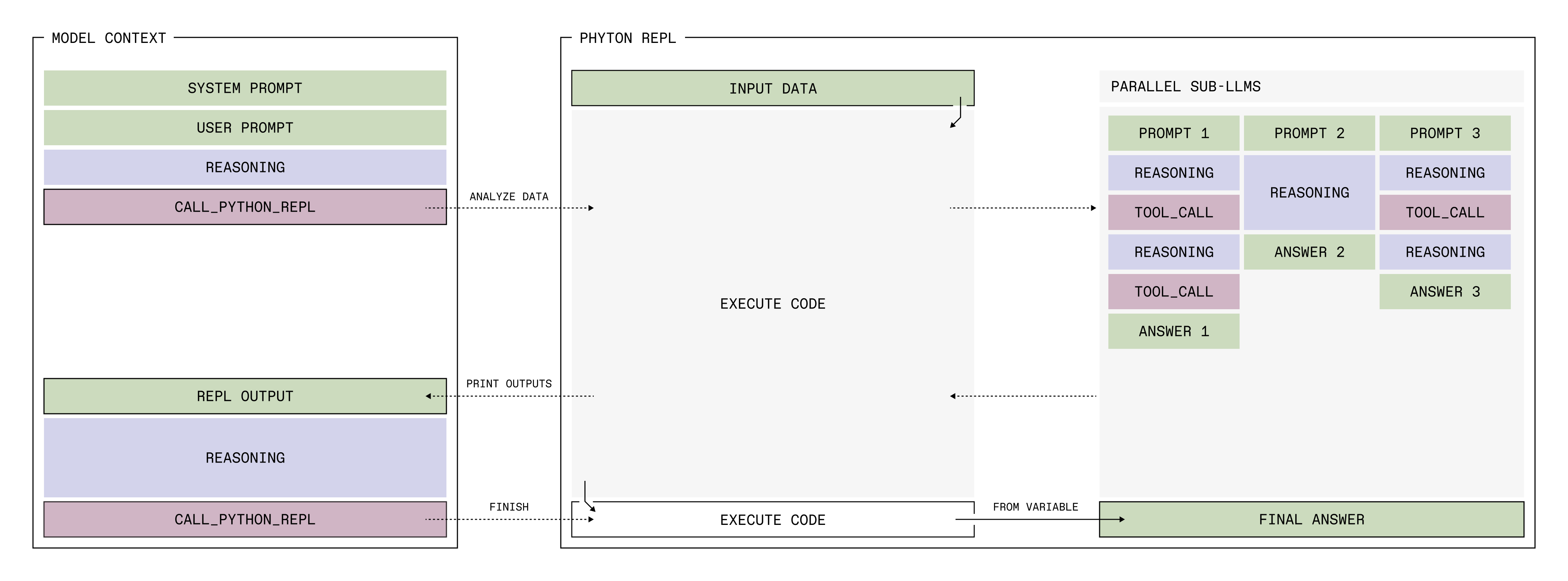
Rather than relying on a single, continuous exchange between a user and a model, the pattern that has emerged in tools like Claude Code and OpenAI's Codex is similarly instructive. These tools use what is known as 'scaffolding', acting as an intermediate layer that decomposes a complex task into a series of steps, stores the evolving state of work in files and compresses accumulated context through periodic LLM-generated summaries before passing it forward. The result is a succession of agents, each receiving a focused brief assembled from the current state of a shared file system and the output of the previous step.
This structural approach reflects a broader principle researchers describe as 'context folding'. Rather than expanding the context window indefinitely and hoping the model can navigate it, the task is folded into smaller, self-contained units, each of which receives the model's full attention. Recursive language models are one practical expression of this principle.
Breaking the Prompt Into Parts
Where a traditional prompt attempts to hold an entire task in a single context window, recursive prompting treats each constituent part of that task as a discrete, manageable unit. The model focuses fully on each part in turn, rather than spreading its attention across everything at once. Each sub-task is submitted as its own prompt, with its own clear objective, its own relevant context and its own output format. The results are then assembled into a coherent whole.
The same structural logic appears in AI-powered search. When an LLM receives a complex query, it does not attempt to answer it as a single lookup. Instead, it fans the query out into multiple focused sub-queries and synthesises them into a unified response. Recursive prompting applies this same fan-out logic to task generation rather than information retrieval.
By treating each element as an individual building block, each sub-prompt draws on the variables it needs and ignores the ones it does not. That precision pays dividends beyond the quality of any single output. When a response is weak or misaligned because the model's attention was stretched across an overloaded prompt, the natural response is to submit the task again, often with additional clarification. Each reprompt consumes further tokens and compounds the original inefficiency. Recursive prompting addresses this at the source. As each sub-prompt is focused and the context is clean, outputs are more reliably usable the first time. Fewer iterations are needed, which means fewer tokens consumed, less time spent correcting and a more predictable workflow overall.
The growing ability for LLMs to manage their own working context through end-to-end reinforcement learning frameworks requires a shift in approach to how AI interactions are structured. Rather than finding the fastest path from prompt to output, the goal is to engineer a reliable, repeatable process that produces work of strategic quality with fewer cycles of correction. This demonstrates why investing time in preparing a highly structured prompt to frame a task before delegating it to AI gives something very precise for AI to work with. A rushed brief will only provide basic results that erode some of the productivity gains that AI-assisted work is designed to enable.
At the same time, as AI use continues to scale, the growing pressure placed on server capacity is already visible. A case in point is Anthropic's decision in March 2026 to adjust its session limits during peak weekday hours (5am to 11am PT / 1pm to 7pm GMT), meaning users could exhaust five-hour session allowances faster than usual during those windows. For businesses, this is a wake-up call as to the cost of inefficient prompting as an increasingly significant operational issue.
The Case for a Prompt Library
As recursive prompting depends on well-structured prompts, the quality of those prompts becomes the primary determinant of output quality. This is important since most teams operate with informal prompting habits. Individual staff members develop their own approaches based on what works for them. When they move on, that learning disappears. When a colleague attempts the same task, they start again from scratch. The result is inconsistency across outputs and an organisation that doesn't accumulate the prompting knowledge it is continuously generating.
A prompt library changes this. It is a structured, shared repository of tested prompt templates and usage guidance, maintained collaboratively across a team. Each entry documents not just the prompt itself but the task it was designed for, the output it reliably produces and an honest assessment of how well AI was able to complete it. That last element, the honest assessment, is perhaps the most important and the most commonly omitted. A tool that produces a competent first draft is doing something different from one that reliably generates analytically rigorous strategic analysis. Teams that document what AI does well, and where it consistently falls short, make better decisions about where to invest human editorial effort.
A prompt library also serves as a vehicle for quality standards across a team. If brand voice guidelines are codified as a reusable prompt component, then every content output that draws on that component reflects the same foundation. If an analytical framework is documented as a variable, it does not need to be reconstructed each time a similar task arises.
The investment in building this organisational prompting guidance is modest relative to the return. It requires someone to take ownership of it, a shared documentation tool and a culture of contribution and active reflection. Yet, what it produces is an organisation whose AI capability compounds over time.
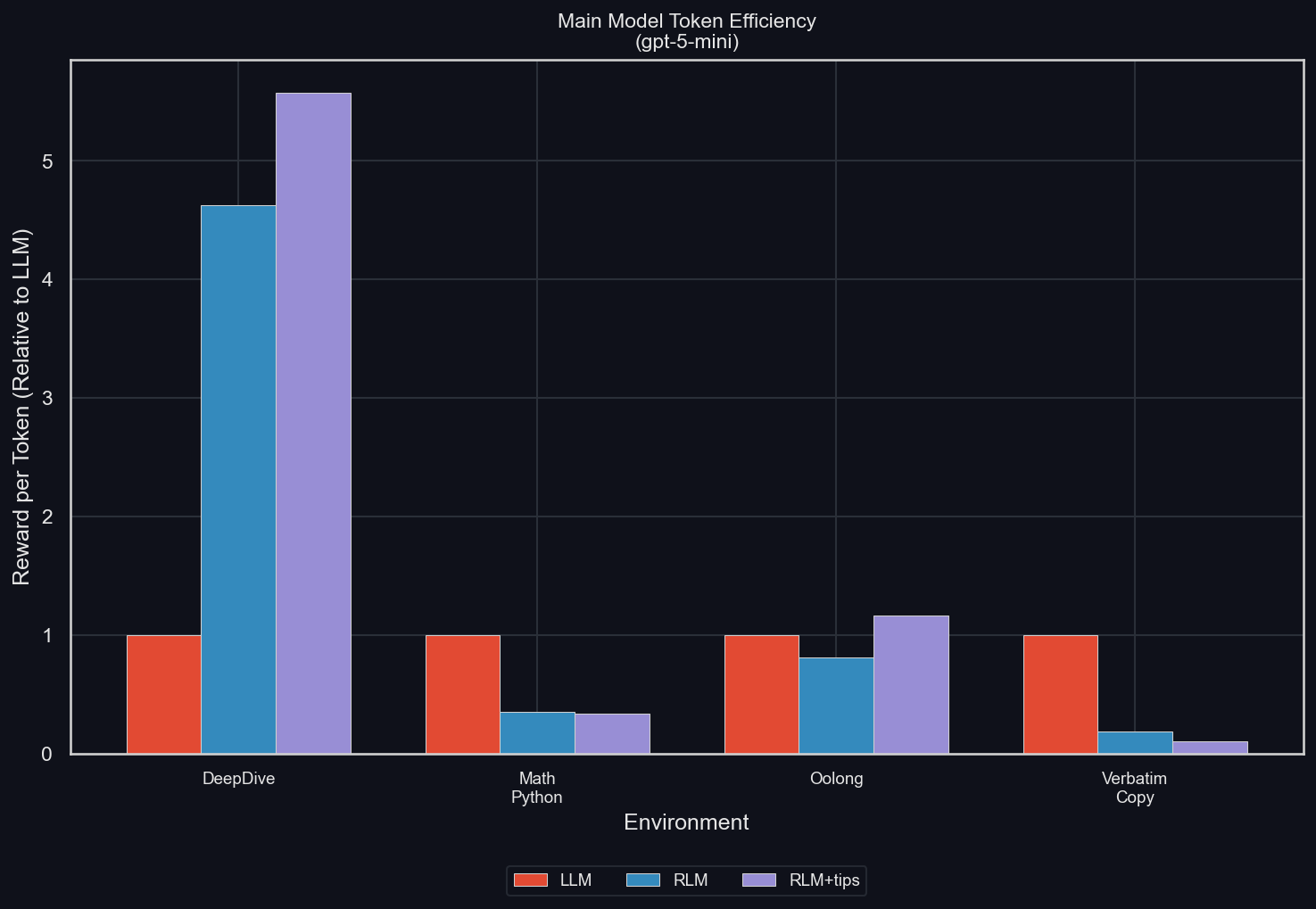
Main Model Token Efficiency
As AI becomes embedded in working processes at scale, teams will need ways to measure whether it is working. Output quality is one dimension. Speed is another. A third metric that deserves more attention than it currently receives is the main model token efficiency.
Token efficiency is a measure of how much useful work a model produces per token consumed. The ratio of meaningful output to total tokens consumed gives an indication of how well a given model performs for a specific task. It is also worth noting that model capability does not improve uniformly across benchmarks. A model that scores well on general reasoning tasks may show little or no improvement on specific analytical, creative or domain-specific work. This inconsistency across task types means token efficiency and output reliability vary considerably depending on what AI has being asked to do.
Teams that test models against their own workloads are far better placed to make decisions that hold up in practice. Token efficiency matters for two reasons. The first is financial. Any team using AI at scale will consume tokens in volume, and efficiency differences between models or between prompting approaches translate directly into cost differences.
The second reason is strategic. Token efficiency reflects the alignment between a model's training and the tasks being asked of it. A model that performs efficiently on conversational queries may be considerably less efficient on analytical tasks requiring structured reasoning. That mismatch only surfaces when teams measure against their own task types rather than relying on general-purpose benchmarks.
Putting It Into Practice
Recursive prompting, prompt libraries and token efficiency measurement are not individually transformative ideas. Taken together, they represent a coherent approach to AI use that addresses the real constraints teams face: declining quality in complex tasks, rising costs at scale and the inability to accumulate and share learning across an organisation. Getting there means shifting attention from what to ask to how AI interactions are structured.
For team leaders, this sits at the intersection of technology and organisational practice. What governance structure is being built around your AI tools? Who owns the prompt library? How is quality being measured? Are people sharing what they learn?
Those questions matter because AI capability, used this way, compounds. Every well-documented prompt is a building block. Every honest assessment of what worked and what did not is a small piece of institutional knowledge. Teams that invest in that infrastructure early find that the models improving around them only make it more valuable. Those relying on individual habits tend to find that AI keeps falling slightly short of what they hoped, without quite being able to say why.
Oops! Something went wrong while submitting the form.
The same AI model, given broadly similar tasks on different days, produces results that vary considerably in quality, depth and usefulness. That inconsistency is a direct consequence of how large language models (LLMs) are structurally designed to process a request. Every word is first converted into a numerical unit called a token, roughly equivalent to four characters of text. Non-English text, however, typically uses more tokens. The model processes those tokens through a mechanism called attention, which determines how much weight each token gives to every other token in the input.
The Cost of Complexity
When a prompt is short and well-scoped, attention distributes cleanly across it. Yet, as a prompt grows longer, including more instructions and background information, the model's ability to maintain coherence begins to decline as there are more signals to balance. The quality of its output reflects that enhanced load. A 2024 study found that model performance degrades by more than 30% when relevant information sits in the middle of a long context, even in models explicitly designed for extended inputs.
This means that feeding a language model an enormous amount of background text is a bit of a double-edged sword. More context can sharpen the results, but it also gives the model far more to trip over, which can actually dent its accuracy. Does the extra context add real value or does the model simply lose its way when the input gets too heavy? The answer usually comes down to the specific task.
This widely observed but underappreciated phenomenon is known as context rot, where the output reflects the dilution of the prompt requirements. Maintaining quality as task complexity grows, while keeping costs manageable as volume increases, points to the need for restructuring how the interaction is built rather than hunting for a cheaper model or writing shorter prompts. The impact of context rot can be limited to a certain degree by positioning the most relevant information at the start or end of a prompt, necessitating a clear overview of which factors have the highest strategic importance right from the outset of a task.
A further complication is that teams rarely have clear visibility into how many tokens a given interaction will actually consume before it runs. Usage depends on the length and complexity of the conversation, the features in use and which model is selected, without specifying a precise figure in advance. This uncertainty makes overloaded prompts doubly costly as they are difficult to budget for.
In most LLMs, each attention weight is determined by comparing a single query token against a single key token. This one-to-one matching places a ceiling on how much information the model can use when deciding which parts of a prompt are relevant to a given output.
From Single Prompts to Structured Workflows
Meta's research into Multi-Token Attention (MTA) proposes a direct solution. Rather than each token attending independently, MTA blends them together and allows neighbouring tokens to influence each other's attention weights. The result is a model that locates relevant context using richer, more nuanced signals. This means the model is better equipped to handle complex, layered prompts, where meaning is distributed across multiple sentences rather than concentrated in a single phrase.
Rather than relying on a single, continuous exchange between a user and a model, the pattern that has emerged in tools like Claude Code and OpenAI's Codex is similarly instructive. These tools use what is known as 'scaffolding', acting as an intermediate layer that decomposes a complex task into a series of steps, stores the evolving state of work in files and compresses accumulated context through periodic LLM-generated summaries before passing it forward. The result is a succession of agents, each receiving a focused brief assembled from the current state of a shared file system and the output of the previous step.
This structural approach reflects a broader principle researchers describe as 'context folding'. Rather than expanding the context window indefinitely and hoping the model can navigate it, the task is folded into smaller, self-contained units, each of which receives the model's full attention. Recursive language models are one practical expression of this principle.
Breaking the Prompt Into Parts
Where a traditional prompt attempts to hold an entire task in a single context window, recursive prompting treats each constituent part of that task as a discrete, manageable unit. The model focuses fully on each part in turn, rather than spreading its attention across everything at once. Each sub-task is submitted as its own prompt, with its own clear objective, its own relevant context and its own output format. The results are then assembled into a coherent whole.
The same structural logic appears in AI-powered search. When an LLM receives a complex query, it does not attempt to answer it as a single lookup. Instead, it fans the query out into multiple focused sub-queries and synthesises them into a unified response. Recursive prompting applies this same fan-out logic to task generation rather than information retrieval.
By treating each element as an individual building block, each sub-prompt draws on the variables it needs and ignores the ones it does not. That precision pays dividends beyond the quality of any single output. When a response is weak or misaligned because the model's attention was stretched across an overloaded prompt, the natural response is to submit the task again, often with additional clarification. Each reprompt consumes further tokens and compounds the original inefficiency. Recursive prompting addresses this at the source. As each sub-prompt is focused and the context is clean, outputs are more reliably usable the first time. Fewer iterations are needed, which means fewer tokens consumed, less time spent correcting and a more predictable workflow overall.
The growing ability for LLMs to manage their own working context through end-to-end reinforcement learning frameworks requires a shift in approach to how AI interactions are structured. Rather than finding the fastest path from prompt to output, the goal is to engineer a reliable, repeatable process that produces work of strategic quality with fewer cycles of correction. This demonstrates why investing time in preparing a highly structured prompt to frame a task before delegating it to AI gives something very precise for AI to work with. A rushed brief will only provide basic results that erode some of the productivity gains that AI-assisted work is designed to enable.
At the same time, as AI use continues to scale, the growing pressure placed on server capacity is already visible. A case in point is Anthropic's decision in March 2026 to adjust its session limits during peak weekday hours (5am to 11am PT / 1pm to 7pm GMT), meaning users could exhaust five-hour session allowances faster than usual during those windows. For businesses, this is a wake-up call as to the cost of inefficient prompting as an increasingly significant operational issue.
The Case for a Prompt Library
As recursive prompting depends on well-structured prompts, the quality of those prompts becomes the primary determinant of output quality. This is important since most teams operate with informal prompting habits. Individual staff members develop their own approaches based on what works for them. When they move on, that learning disappears. When a colleague attempts the same task, they start again from scratch. The result is inconsistency across outputs and an organisation that doesn't accumulate the prompting knowledge it is continuously generating.
A prompt library changes this. It is a structured, shared repository of tested prompt templates and usage guidance, maintained collaboratively across a team. Each entry documents not just the prompt itself but the task it was designed for, the output it reliably produces and an honest assessment of how well AI was able to complete it. That last element, the honest assessment, is perhaps the most important and the most commonly omitted. A tool that produces a competent first draft is doing something different from one that reliably generates analytically rigorous strategic analysis. Teams that document what AI does well, and where it consistently falls short, make better decisions about where to invest human editorial effort.
A prompt library also serves as a vehicle for quality standards across a team. If brand voice guidelines are codified as a reusable prompt component, then every content output that draws on that component reflects the same foundation. If an analytical framework is documented as a variable, it does not need to be reconstructed each time a similar task arises.
The investment in building this organisational prompting guidance is modest relative to the return. It requires someone to take ownership of it, a shared documentation tool and a culture of contribution and active reflection. Yet, what it produces is an organisation whose AI capability compounds over time.
Main Model Token Efficiency
As AI becomes embedded in working processes at scale, teams will need ways to measure whether it is working. Output quality is one dimension. Speed is another. A third metric that deserves more attention than it currently receives is the main model token efficiency.
Token efficiency is a measure of how much useful work a model produces per token consumed. The ratio of meaningful output to total tokens consumed gives an indication of how well a given model performs for a specific task. It is also worth noting that model capability does not improve uniformly across benchmarks. A model that scores well on general reasoning tasks may show little or no improvement on specific analytical, creative or domain-specific work. This inconsistency across task types means token efficiency and output reliability vary considerably depending on what AI has being asked to do.
Teams that test models against their own workloads are far better placed to make decisions that hold up in practice. Token efficiency matters for two reasons. The first is financial. Any team using AI at scale will consume tokens in volume, and efficiency differences between models or between prompting approaches translate directly into cost differences.
The second reason is strategic. Token efficiency reflects the alignment between a model's training and the tasks being asked of it. A model that performs efficiently on conversational queries may be considerably less efficient on analytical tasks requiring structured reasoning. That mismatch only surfaces when teams measure against their own task types rather than relying on general-purpose benchmarks.
Putting It Into Practice
Recursive prompting, prompt libraries and token efficiency measurement are not individually transformative ideas. Taken together, they represent a coherent approach to AI use that addresses the real constraints teams face: declining quality in complex tasks, rising costs at scale and the inability to accumulate and share learning across an organisation. Getting there means shifting attention from what to ask to how AI interactions are structured.
For team leaders, this sits at the intersection of technology and organisational practice. What governance structure is being built around your AI tools? Who owns the prompt library? How is quality being measured? Are people sharing what they learn?
Those questions matter because AI capability, used this way, compounds. Every well-documented prompt is a building block. Every honest assessment of what worked and what did not is a small piece of institutional knowledge. Teams that invest in that infrastructure early find that the models improving around them only make it more valuable. Those relying on individual habits tend to find that AI keeps falling slightly short of what they hoped, without quite being able to say why.
Continue reading...
Get access to 100s of case studies, workshop templates, industry leading events and more.